

Clive - Hannon Hill Engagement Tool Built with Fauna
Hannon Hill is known for its Content Management System called Cascade CMS, which comes in the form of an instance installed on a machine. This works well because Cascade CMS is a push CMS, meaning only a handful of content managers log in to the system while the duty of serving live data to potentially millions of website visitors is decoupled and delegated to web servers.
However, Hannon Hill's newest product —Clive, a digital engagement and personalization tool is designed to serve live content directly to the visitors, which means that with a popular enough website, a single machine would not be able to handle all the demand. Because of that, a more scalable solution is required. Instead of taking care of load balancing and manually scaling servers and a database, we have decided to use something different — we decided to go the serverless route, and a stack with AWS Lambda and Fauna turned out to be the best solution.
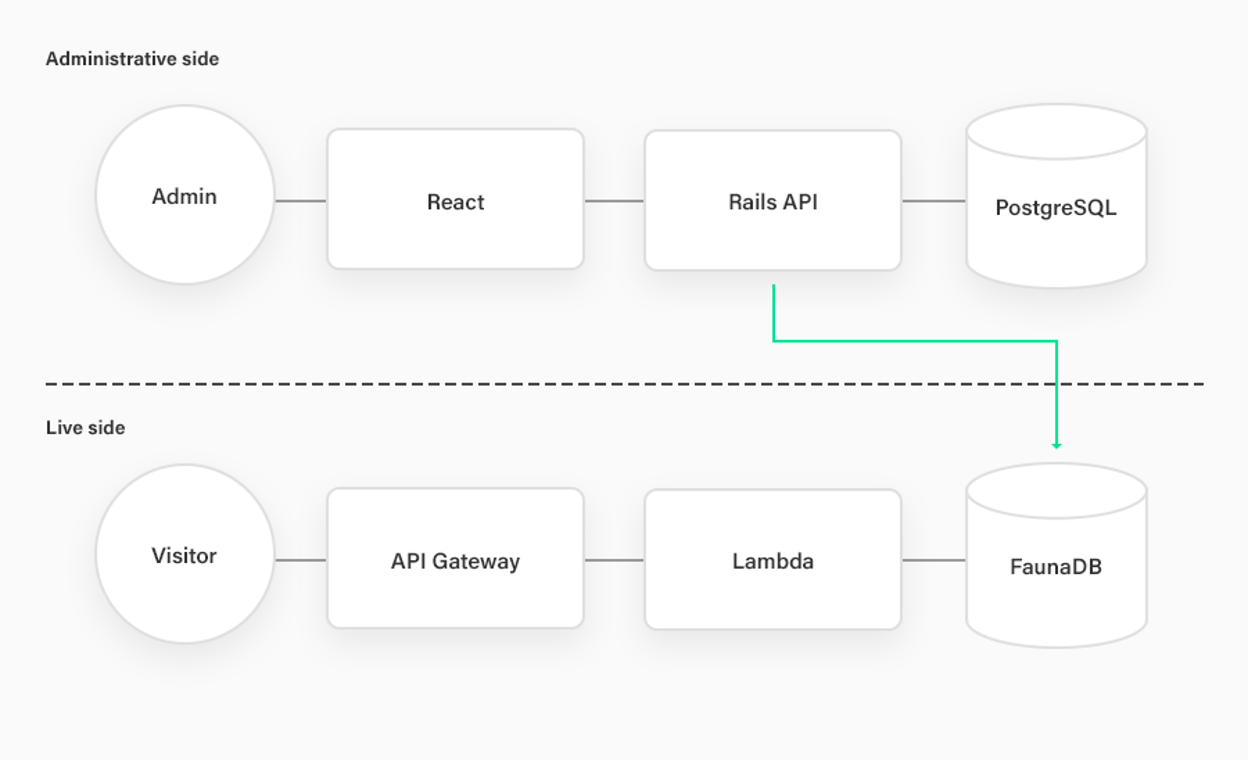
Stack Overview
Clive's administrative application accessed by Clive content managers runs on a tried and true, non-serverless solution — Ruby on Rails. Rails pushes data to Fauna through the Fauna Ruby gem, so that the content is then available for Live API.
On the other hand, the Live API that serves live content to visitors runs on a true serverless stack - AWS Lambda behind an API Gateway with TypeScript and NodeJS Fauna library. This allows seamless auto-scaling without any worry — no matter if websites are accessed by several visitors per hour or several millions of visitors per hour, the content will be served without any hiccups.
To be able to easily publish AWS Lambda functions, we use the Serverless framework, with some additional plugins that allow us to develop locally and deploy quickly.
Why Serverless?
Clive gave us the opportunity to modernize our architecture (in parts). Instead of the classic three-tiered architecture, we chose to go serverless with Clive, to avail of these following benefits: :
Auto-scaling: Both in terms of being able to handle a large number of requests in parallel (throughput) and in terms of max database size.
We currently handle traffic from as low as 5k requests per hour up to 50k requests per hour depending on the time of the day and we expect the numbers to grow.
Cost savings: Costs based on usage with zero cost when there is zero or near-zero usage; no need to pay for minimum or pre-defined throughput.
API gateway costs $3.50 per million requests while Lambda averages out to around $1.00 per million requests. $4.50 per million at an average of 30k requests per hour calculates to $0.135 per hour, which is pricing of somewhere between c5.large and c5.xlarge instances. A legacy non-serverless product we maintain that handles similar load runs currently on 3 c3.xlarge machines that unreserved cost $0.210 per hour. At $0.630 per hour the legacy product costs us almost 5 times as much as Clive does.
Time savings: No need to maintain the underlying operating system, perform upgrades, etc., the database as a service is made available through an easy-to-use API.
We average out about 10 hours a month spent on maintaining servers of the legacy non-serverless product while maintenance related tasks for Fauna and Lambda were related to client and NodeJS version upgrades less frequently than once a year.
Using Fauna for Clive
While PostgreSQL serves the administration side and stores administration related data, such as Account, Users, Configurations, etc., Fauna serves the live side and stores live data, such as Forms, Form Submissions, Visitors, Page Views, etc. Thanks to this distinction, if PostgreSQL is down for any reason, live websites are not affected since all the necessary data is available in Fauna. Likewise, if Fauna is down for any reason, users can still use the administrative app to log in and manage content. Content managed by the administrative side but needed by the live side, such as Forms, is synchronized with Fauna in the background.
Thanks to the fact that Fauna clients are available in many programming languages, including Ruby, the administrative side is able to fetch the live data and present it to administrators directly, without a need for additional network hops (Ruby->Fauna as opposed to Ruby->Lambda->Fauna).
Some of our client Accounts have already accumulated many millions of Visitors, Visits and Page Views. Fauna allows administrators to browse that data quickly using cursor-based pagination, no matter what page the user is currently viewing and no matter how big the dataset is. This is a clear improvement over Spectate’s MySQL where loading large data tables with hundreds of pages was resulting in slugging performance.
Fauna handles parallel transactions very nicely as well. Thousands or millions of Visitors can be accessing client websites at the same time, yet no transactional blocking errors occur (such as "Lock wait timeout" errors that we are familiar with from CascadeCMS). Transactional blocking functions properly regardless, preventing creation of duplicate documents, double counts etc., without much of an effort. This is a much better developer experience compared to MySQL where we were running into issues with transactional blocking and we had to spend a good amount of time tweaking locking levels to get things to work right - not cause too much contention, yet not create duplicates. A simple example of a seamless transactional locking is the typical "If(Exists(), Create(), Update())" query. With default transactional locking levels MySQL is capable of creating duplicate rows when using corresponding "select", "insert" and "update" queries in a transaction if multiple parallel transactions try to insert/update records with the same key, while acquiring a lock on entire table level would quickly result in contention.
At times model/schema changes are necessary. With hundreds of millions of rows, schema updates tend to take a very long time to get applied. To maximize uptime, such updates are typically executed in the background row by row while the app is running. This applies to both MySQL and Fauna. This can be a challenge to implement, since the app needs to be able to handle the data in both schema formats. Thanks to the fact that Fauna documents do not have to follow a specific schema, we are able to avoid many such updates altogether, saving us a lot of time, effort and saving our users from running into potential bugs.
Conclusion
Fauna was able to save us a good amount of DevOps time that we would have otherwise spent on building a scalable solution and maintaining or managing database servers. Because it can handle large volumes of load and it can quickly query from large volume data, our product performs smoothly at all times. The team at Fauna has been quick to respond to our issues, while introducing new functionality at a regular cadence. The documentation has helped us operate on an autopilot for the most part, however, we want to extend a huge shout out to the Fauna community of developers. It is one of the most helpful communities I’ve participated in, and we look forward to more collaboration with them.

The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.