

Database Joins for NoSQL
Normalized data models are great
Commonly, the data stored by applications has to fit many purposes. Access methods need both read and write optimization. Usage can be shared between frontend customers and backend services. Security and reliability are mandatory. In short, data modeling needs are complex and put a heavy strain on those responsible for data platforms. To achieve their goals, data modelers prefer normalizing. Breaking data out into separate, logical entities that can dynamically fit the aggregated or isolated access needs of all. Bringing data back together is as simple as a single interaction using a join to rehydrate relationships. Data access is scoped, optimized, dynamic and simple.
So, if normalized data models are so useful, why don’t NoSQL databases make them as easy as relational databases? Sure, you can store data in separate documents, which appears normalized. But, either managing the consistency of multi-document writes isn’t an option, or transactional features add significant cost. And, bringing the data back together requires either multiple database interactions (“application joins”) or pre-compiled, (thus rigid) views. The lack of native multi-document transactions and native joins in NoSQL databases pushes the complexity of real-world business operations to developers and applications.
Why don’t NoSQL databases natively support normalized models?
The blocker for NoSQL joins is based on how they store data. To satisfy the scale of web and mobile applications, NoSQL databases utilize processing parallelization and resource distribution. They therefore purposefully distribute the storage of individual documents over many physical hardware nodes. While this is great for the scale of parallel operations, there is no guarantee that separate documents are on the same physical resource. This means that distributed joins would then be slow and inconsistent. Essentially, everything works great as long as every interaction is associated with only one document. This then pushes the work of applying multiple writes and/or traversing many reads to the application.
What really matters to a business application:
- Net Operation Time (N.O.T.): The total time it takes to do a complete application operation (retrieve data from all documents, perform any calculations and write all mutations). From the application’s and user’s perspective, N.O.T. is the latency of the whole operation, not just a single database interaction in an overall business operation.
- Data integrity/consistency/reliability: The data service is always there. Any data mutations are accurate. Reads are globally consistent. Bonus points for platforms that offer native multi-line transactions and server side functions.
- Cost: TCO of the full impact of the database. When all of the features, cost multipliers, data copies, table rebuilds and developer-forced complexities are accounted for.
- Model optionality: This affects time-to-delivery (how long it takes to start up, how long it takes to make changes, etc), effort (time to create models that work both for the application and the database) as well as risk (removing inconsistencies, rebuilding collections to apply new requirements, etc).
- Security: Role and attribute based permissions are more targeted and provide more comprehensive access control by normalizing (isolating) data and using joins to dynamically retrieve only the required elements, not whole documents,.
Database joins are amazing!
One of the best things about normalized data models is the ability to join the various data bits back together in a simple, fast and flexible manner (through queries). Further, being able to use one interaction to dynamically pull just the data needed from multiple documents is a huge value to apps. Here are some of the benefits of leveraging joins in your data model:
- Net Operation Time (N.O.T.) can be dramatically reduced by grabbing all data needed in a single interaction. This requires either joins or server-side functions. While Fauna has both, joins are the dynamic, simple and flexible means for gathering data from more than one document/collection.
- Net data sizes of reads are reduced leading to faster and cheaper operations. Bring back only the data needed, in one query.
- Application code can be simplified.
- Queries can be dynamic and flexible.
- Allow for index optimization. Index just entry points and connecting keys to reduce the size, complexity and costs of accelerating access patterns.
Fauna brings back database joins
Fauna’s unique document-relational engine natively supports joins, enabling optionality in data models. Embedded or related, your choice. We do this with two key innovations.
- Optimized document storage. By separating the compute layers of the engine from the data storage layer as well as making every storage call extremely fast, Fauna’s engine traverses multiple documents in one query with blazing speed. Like a relational database, push down a single query and skip the network latency of multiple interactions.
- Native reference traversing. Fauna’s engine will take the data elements requested in the query and auto-traverse from document to document resolving reference IDs. Like a relational database, use a single query interaction to simplify data access.
Now pulling together data from multiple documents is fast, flexible and developer friendly.
Take the example of an eCommerce database or SaaS database that’s using normalization/relations for their customer, order, and product application data. With Fauna, a single query statement (database interaction) can gather a dynamic, flexible and optimized set of data, via joins, from all three documents.
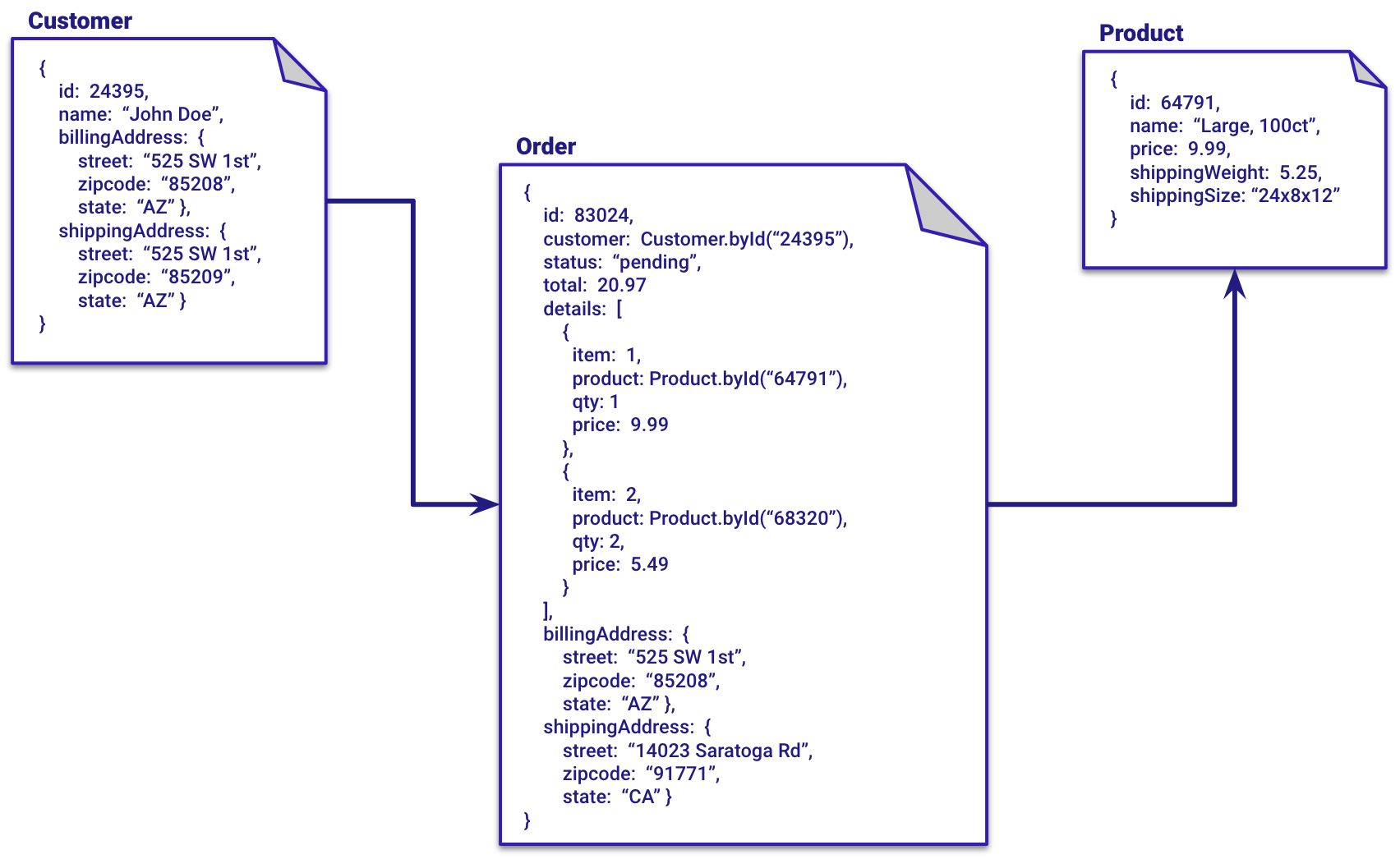
Order.byId(83024) {
total,
customer {
name
},
details {
qty,
price,
product {
name
shippingWeight
}
}
billingAddress
}With Fauna, a developer can use one database interaction instead of many, optimize the data returned, access data via many patterns and quickly adjust interactions as needed.
It should also be mentioned that Fauna rounds out the relational capabilities combined with NoSQL scale by offering limitless & enhanced indexes, natively allowing schema enforcement, supporting computed fields, native server-side functions and offering databases as logical containers (excellent for multi-tenancy, scoping permissions).
Common patterns for joins
Modeling data’s relationships are just one of several considerations for an architect. Equally as important to a data model are data volatility and access patterns.
- Volatility: How often data will change. Either an element of an object or an item in an array, how they change can affect whether they’re better stored in isolation (normalized) or embedded. Embedding is great for items that rarely change or lists that do not grow that large. But for large and growing lists (like order history) or frequently changing items (like order shipping status), normalizing allows for both write and read optimization.
- Access patterns: Who, when, and how data will be accessed can also significantly influence the optimal models for data storage. Multiple services may need the same data (like customers and shipping companies needing access to order details) but require different return sets for optimization of interactions and security/permissions. Normalizing the data model and joins allow for fine grained access control, efficient data transfer, optimized indexes, and flexible access patterns.
Summary
As databases moved to horizontal scaling to support higher workloads they lost the ability to join separate objects. This tradeoff led to applications and developers taking over the work of a database and pushing latency, risk, cost, complexity and consistency challenges up the stack. By adding efficient, low-latency joins on top of a document database, developers get the best of all worlds. Fast, efficient, cost effective, flexible and secure infrastructures.
Ready to get started building with Fauna? Sign-up for a free Fauna account, check out the Fauna community forums to engage with fellow builders, and get in touch if you have any questions!
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.