

Edge computing reference architectures
Cloud computing has transformed how businesses conduct their work, but many face challenges regarding data protection (residency and sovereignty), network latency and throughput, and industrial integration. On-premises infrastructure, especially when it’s tightly integrated with edge computing services provided by various cloud platforms such as AWS Lambda@Edge, Cloudflare Workers, Fastly Compute@Edge, etc., can be helpful in solving these problems. But that’s just part of the edge computing puzzle.
Cloud data centers and on-premises infrastructures form the near edge of the network. The other part of the network can be considered the far edge. Many businesses need the last mile coverage of the cloud to ensure that the cloud connects and integrates directly with controllers, sensors, and far-end devices. Currently, this workload is handled by specialized programmable logic controllers (PLCs) and human-machine interfaces (HMIs). These devices work great but depend on proprietary operating systems and are costly to acquire, maintain, and upgrade.
The following table lists the different parts of an edge network and their usual distance from the devices on the far edge of the network, along with the network latency from applications to those devices:
- The cloud (regional and zonal data centers) — is 10+ km away from edge devices and has a latency of over 10 ms
- Near edge (on-prem data centers) — is between 1 to 10 km away from the edge devices and has a latency from 1 to 10 ms
- Far edge L1 (gateways, controllers) — is between 10 m to 1 km with a latency of somewhere between 0.1 ms and 1 ms
- Far edge L2 (sensors, devices) — is in the 10 m range of the edge devices and has sub-millisecond latency
This article will take you through some of the edge computing reference architectures proposed by different organizations, researchers, and technologists so that you have a better understanding of the solutions that edge computing offers.
Why do you need edge computing?
Content delivery networks are based on the idea that to provide a great user experience, you need to deliver the content as quickly as possible. You can only do that by physically bridging the network latency gap to place the content closer to your end users. Fast-access storage solves this problem. Big companies in specific domains like content delivery and mobile networking already use the edge network for storage, if not for computing.
But many businesses can’t solve their problems with delivery networks; they need computing power without the latency lag of the cloud. They would rather have something closer to the edge in addition to the cloud.
Edge computing use cases
Take vehicle autonomy, for instance. An average car without autonomy has over fifty sensors that help the vehicle’s critical and non-critical functions. Traditionally these sensors were lightweight, but with autonomous car cameras, LiDAR sensors, and others, there’s an ever-increasing demand for computing power on board. You can’t rely on APIs and the network for processing specific information in the operations of a critical machine like a car. Another example is surveillance. Businesses might use AI and ML applications to process a camera feed in real time. Offloading that amount of raw data to the cloud for processing might not be the wisest decision, as it will need tremendous network bandwidth and computing power to move data back and forth. To save time spent moving data around, you need more computing power at the source, and you can send the workloads that can wait to the cloud. The same principles apply to many specialized industries, such as aerospace, live entertainment, mass transportation, and manufacturing. This is why the edge is becoming more relevant by the day. Other applications of edge computing include:
- Decoupling automation workloads from specialized hardware like PLCs and HMIs by using open source software like FreeRTOS or OPENRTOS and running the workloads on containers
- Offloading custom data-intensive critical workloads to the near edge network
- Minimizing your maintenance and downtime with a redundant computing system for your business’s critical systems, which adds real value to your business continuity planning (BCP) and disaster recovery planning (DRP) efforts
- Optimizing business processing with the help of faster response times from the computing power on the network’s edge
Interested in understanding edge computing beyond its use in IoT?
Fauna can help you build faster, more performant edge applications. Since Fauna is distributed dy default, you can reduce latency for your apps with a close-proximity database for your edge nodes. Easily integrate with Cloudlfare workers and Fastly Compute@Edge platforms out of the box.
Edge computing reference architectures
To properly design and implement edge computing networks, businesses rely on reference architectures. The following are some reasons why they’re an invaluable resource.
Design considerations
Businesses are still finding different ways to exploit the power of edge computing, and edge computing reference architectures help them understand systems that could potentially work for them. Not only are these reference architecture patterns well researched and thought out by industry experts, but they try to encapsulate the key features that apply to various businesses.
You can use reference architectures for inspiration as well as innovate on top of them. There are several factors and design considerations that you should take into account while architecting an edge computing system for your business:
- Time sensitivity: With edge computing, critical business functions don’t have to wait for workloads to be offloaded to the cloud for processing
- Network bandwidth: Bandwidth is limited; you don’t want to choke the network by blocking other important operations
- Security and privacy: Data sovereignty and data residency, both for security and privacy, can be enabled by the edge
- Operational continuity: During network disruptions, you can offload the extremely critical operations of your business to the edge
Implementation outcomes
The outcomes and benefits of architecting edge computing systems align strongly with the abovementioned factors. With a successfully deployed edge computing system, your business gains the following core benefits:
- Significantly lower latency and higher network bandwidth by utilizing the proximity from the request origin to the computing system
- Effective network use by filtering and reducing farther data transfer to on-premises or cloud infrastructure
- Better enforcement of security and privacy standards, enabling data sovereignty and data residency
Development and deployment plans
When developing for the edge, businesses need to ensure that they don’t end up creating the same dependencies and bottlenecks they experienced when using only on-premises data centers or the cloud.
An excellent way to do this is to research, identify, and pick the right open standards and technologies to help you get the architecture you want. Possible open standards include those for APIs, documentation, virtualization patterns, deployment pipelines, and code promotion strategies.
Edge computing reference architectures that use Fauna
There are many reference architectures, some of which heavily borrow from one another. However, each has a unique approach and feature set. Fauna, as a distributed general-purpose database, interacts well with all of them in different ways.
The following are details on four reference architectures, their relevance and innovation, and how to adopt them with Fauna.
Industrial internet reference architecture
The Industrial Internet Reference Architecture (IIRA) was first developed in 2015 by the Industry IoT Consortium (IIC). This was a collaborative effort from a range of companies, including Bosch and Boeing in manufacturing; Samsung and Huawei in consumer electronics; and IBM, Intel, Microsoft, SAP, Oracle, and Cisco in the software industry.
Think of IIRA as having four different viewpoints: business, functional, usage, and implementation. The system is divided into enterprise, platform, and edge. You have low-level devices in factories or appliances at the edge, connected with the platform tier using low-level APIs. Data collected from these devices flows to data and analytics services and operations users.
The data generated by the edge, along with the data and insights gathered and processed by the platform tier, is consumed by the enterprise tier on two levels: the business domain and app domain. The data in the business domain lands in other systems, such as ERP, and the data in the app domain flows further based on business logic and rules to the business users in the form of mobile apps, browser-based frontend applications, or business intelligence tools.
The following diagram shows the three-tiered approach to IIoT system architecture using IIRA:
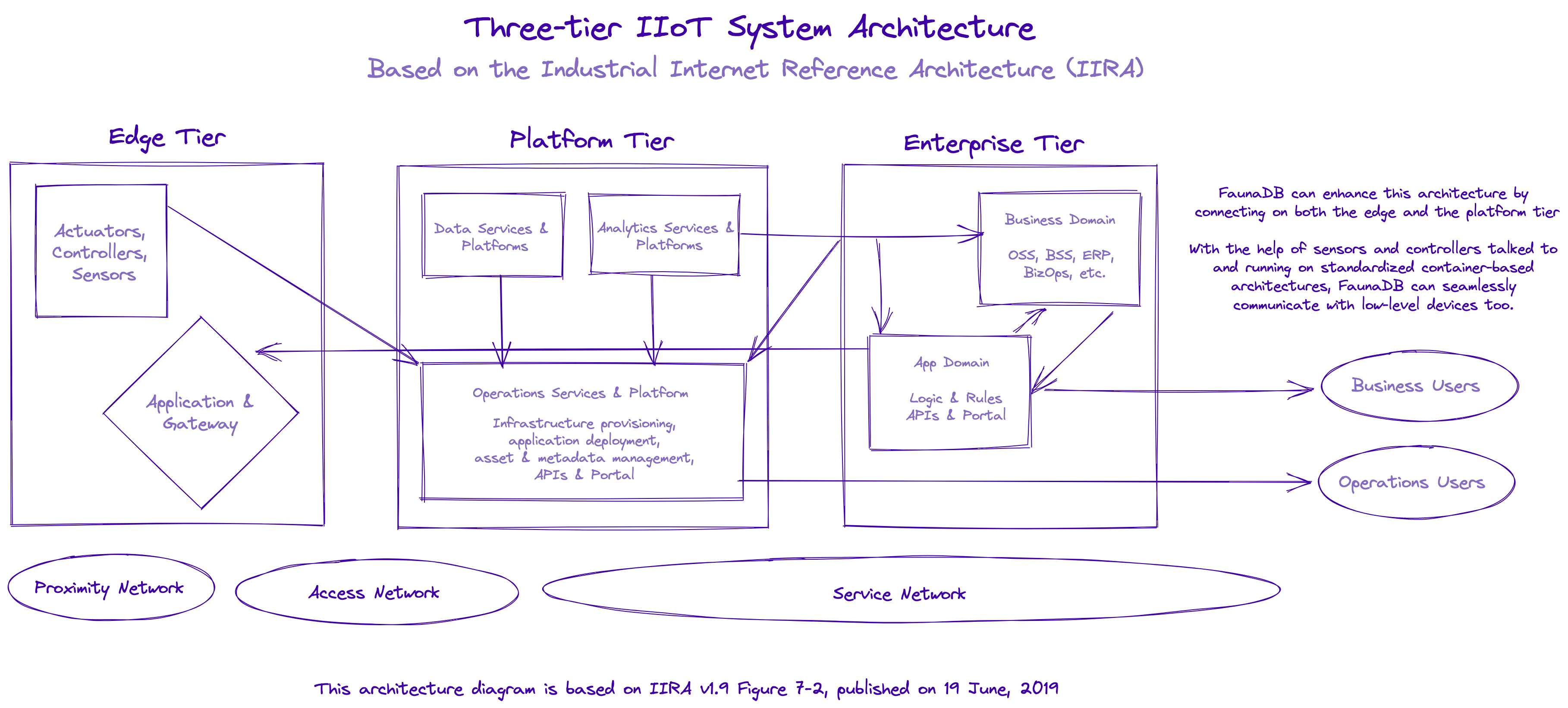
Fauna’s distributed architecture allows it to sit across multiple layers of the network while simultaneously guaranteeing you the privileges of a flexible document-oriented database and ACID transactions. The data and analytics services and platforms can heavily interact with Fauna, and the operations services and platform will do the same. In this context, Fauna sits mainly on the platform tier but interacts with the edge tier, depending on whether the devices are integrated with the platform tier using a virtualization layer.
FAR-EDGE reference architecture
Aside from the previously mentioned features of reference architectures, the FAR-EDGE Reference Architecture brings many new things to the table. It explicitly offers a separate logical and ledger layer that handles processes and rules across the distributed computing system by using the sheer power and spread of the system. Like most edge computing reference architectures, FAR-EDGE also concentrates on saving bandwidth and storage, enabling ultra-low latency, proximity processing, and enhanced scalability by exploiting the distributed nature of the edge-cloud hybrid architecture.
Compare the idea of FAR-EDGE with some of the Web3 architectures built on top of distributed frameworks like the blockchain. Fauna, with its capability to provide edge functions as an extension to the application infrastructure, can play a central role by servicing various layers and functions proposed in this reference architecture. Consider the functional view of the FAR-EDGE reference architecture below:
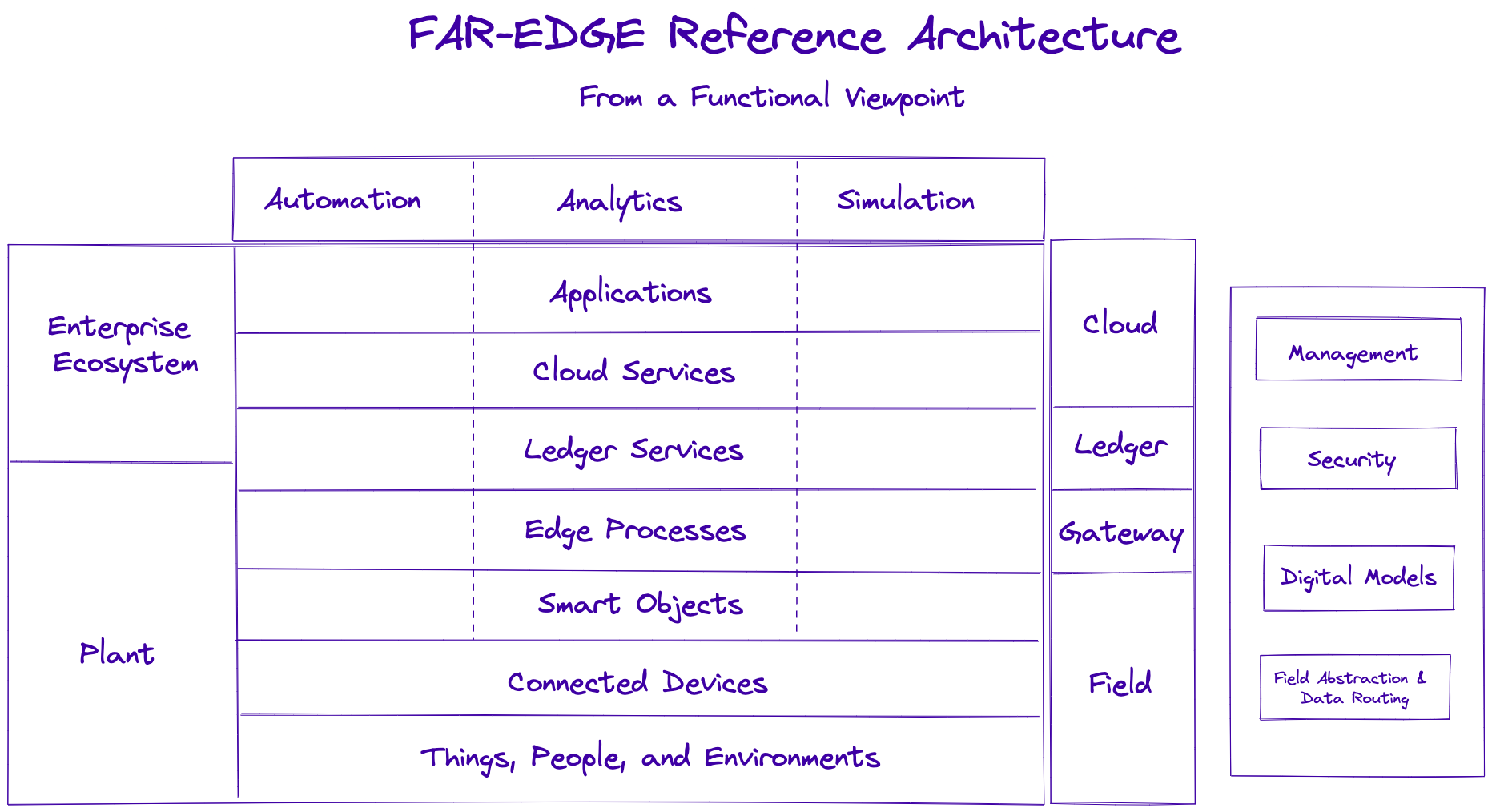
It’s worth reiterating that Fauna is a distributed document-relational database, which is ideal for businesses with a variety of software applications and hardware devices. In this functional view, Fauna will sit and interact not only with applications and cloud services but also with ledger and edge processes at the ledger and gateway levels. You can enable this by using well-documented APIs and SDKs.
Edge computing reference architecture 2.0
The Edge Computing Consortium (ECC) proposed a model-driven reference architecture that attempts to solve the problems businesses face when they try to connect the digital and the physical worlds. Since the reference architecture is multidimensional, you can regard it from different viewpoints. Consider one of its layers, the Edge Computing Node layer, from a functional viewpoint.
The Edge Computing Reference Architecture 2.0 is a multidimensional architecture composed of the following components from a high-level view: smart services, a service fabric, a Connectivity and Computing Fabric (CCF), and Edge Computing Nodes (ECNs).
As mentioned earlier, edge computing thrives when open standards are followed and hardware devices are decoupled from specifically designed hardware. This problem has long been solved for specific web and desktop applications via virtualization. The Edge Computing Reference Architecture also suggests you create an Edge Virtualization Function (EVF) layer that handles connectivity and data streaming and collection, along with access policies and security.
The following diagram of the Edge Computing Reference Architecture 2.0 shows the functional view of an Edge Computing Node (ECN):
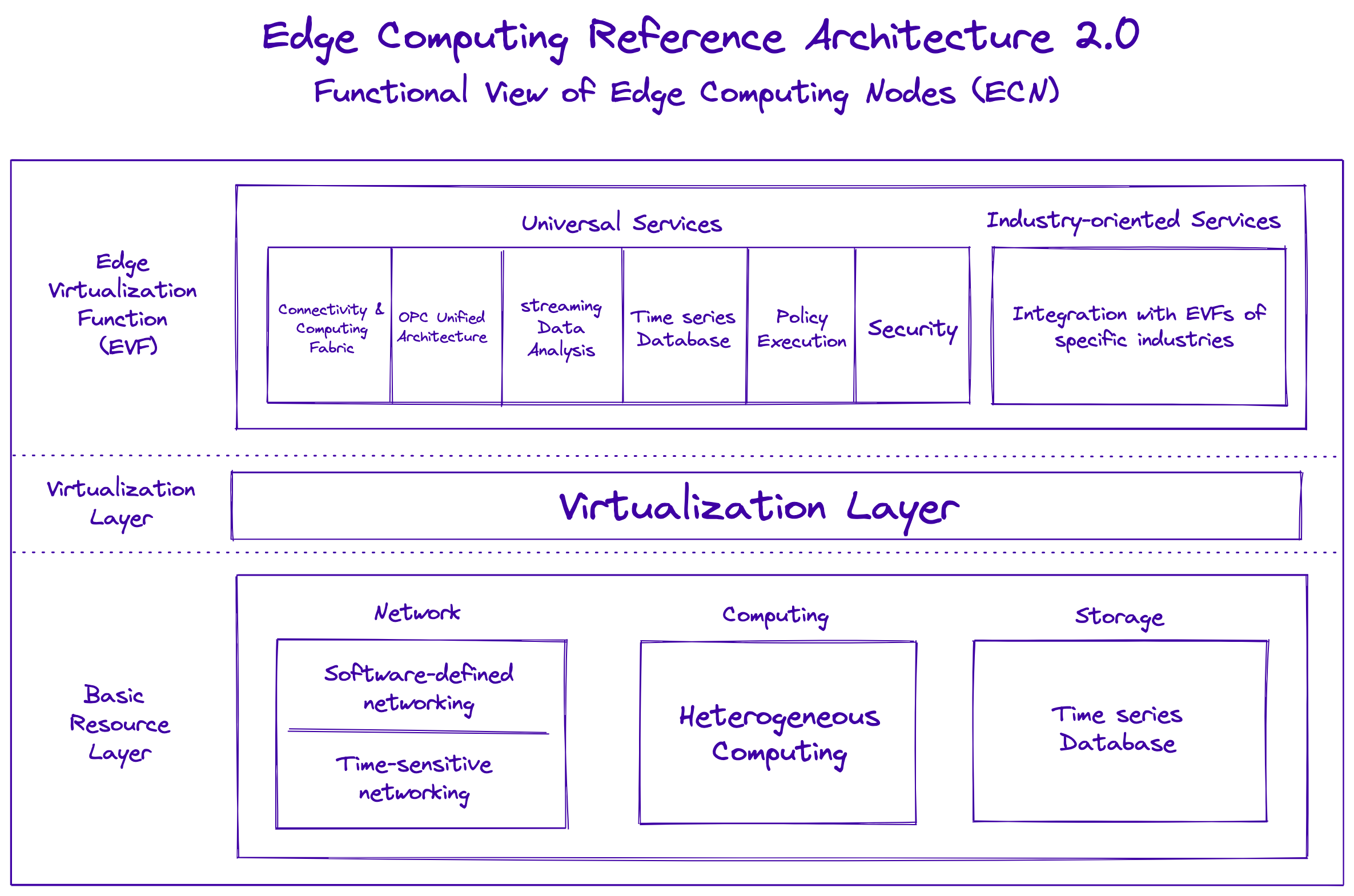
Fauna is more than capable of taking care of the universal services, such as streaming and time series data, along with any industry-oriented services that might need integration.
Conclusion
Edge computing reference architectures can vastly simplify the design and usage of edge computing systems, and Fauna can help at different levels in all these architectures. Fauna is a natively serverless, distributed transactional database that allows for flexible schemas and comes with a well-designed data API for modern applications.
With Fauna in the cloud and at the edge, you can store and retrieve your data at ultra-low latencies while being closer to the source than ever before. With built-in data security, authentication, authorization, and attribute-based access control, Fauna simplifies the implementation of edge computing reference architectures and lets you concentrate more on your business.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.