

SiteGPT: Delivering a globally distributed generative AI application with Fauna, Cloudflare, and Pinecone
Fauna + Cloudflare + Pinecone
Read on to learn how Fauna, Cloudflare, and Pinecone combine to deliver superior performance across the globe for a rapidly growing generative AI chatbot built on OpenAI.
➡️ SiteGPT: A chatbot for the modern internet
➡️ Requirements for developing and scaling a generative AI application
➡️ SiteGPT architecture overview
➡️ Why a distributed and serverless architecture with Fauna, Cloudflare, and Pinecone
➡️ Conclusion
SiteGPT: A chatbot built for the modern internet
Website chatbots have historically offered inconsistent end-user experiences due to limitations in natural language processing (NLP) algorithms, which often resulted in inadequate understanding and response generation. However, with the democratization of access to large language models (LLMs) and other complementary technologies that better harness the power of NLP algorithms, businesses of all sizes can now more cost effectively leverage both semantic search and AI-driven content generation.
Aligned with these developments, SiteGPT Founder Bhanu Teja Pachipulusu sought to help businesses more effectively engage prospects visiting their websites with a more personalized, relevant, and accurate chatbot experience. SiteGPT offers its customers a no-code chatbot implementation approach; SiteGPT customers submit knowledge bases (say, a product’s documentation, frequently asked questions, or other text files) for the SiteGPT engine to train and learn from. Then, SiteGPT provides specifically tailored chatbots that can answer questions and carry conversations in the customer brand’s voice — ultimately helping deliver a better customer experience and increased prospect conversion rate.
Since launching in March 2023, SiteGPT has accumulated significant adoption. It quickly rose to the top spot on Product Hunt, reached $10K in MRR in its first month, and has attracted a rapidly growing user base worldwide. Companies across 11 different countries are now using SiteGPT's chatbots on their websites, with more than 1 million page views per month.
Requirements for developing and scaling a greenfield generative AI application
SiteGPT’s development phase in early 2023 coincided with a rapid adoption of novel generative AI technologies. The corresponding high velocity in company formation mandated that Bhanu and his team prioritize an underlying application stack that was flexible, globally distributed, consistent in storing accurate data, and that can provide the performance interactive users expect. They knew they needed to get to market quickly, but also build their initial product on technologies that they could both rapidly iterate on and scale as their user base grew. Building SiteGPT for scale would mean not only managing high throughput and complex applications, but also efficiently serving users from multiple regions across the globe at low latencies. They needed database tooling that could support disparate forms of data (including vector embeddings, metadata, context, and user application data), and also maintain distribution and latency requirements. Finally, compared to a traditional application architecture, SiteGPT incorporates more novel elements: LLMs and vector databases have only been recently introduced to production workloads over the past few years. This required interoperable systems and tooling that wouldn’t demand performance concessions to manage additional layers of infrastructure. While it was important that the individual components of the stack would be turn-key, API-first solutions that reduced the amount of integration code would help unlock additional value for SiteGPT.
SiteGPT architecture diagram
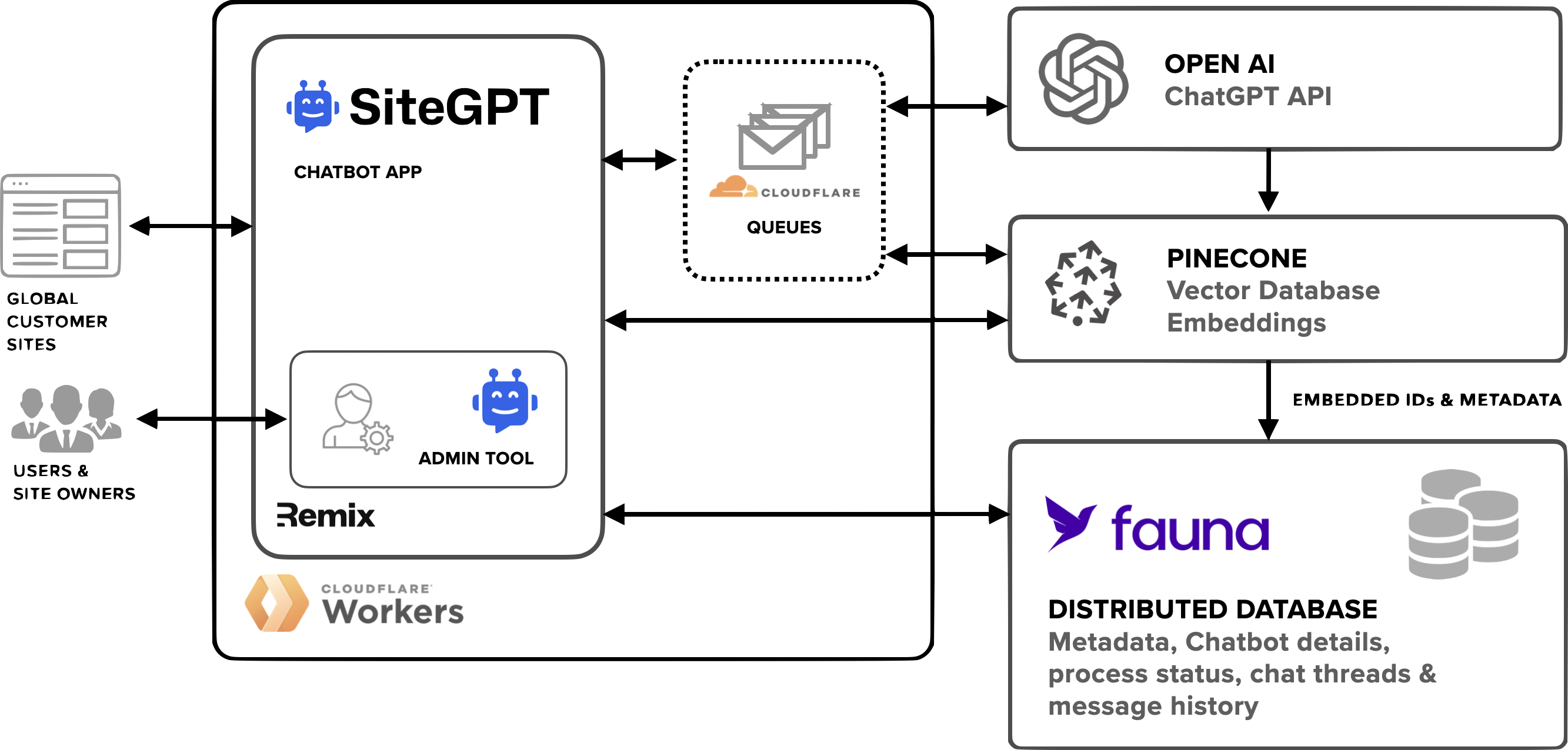
Architecture overview and workflow
SiteGPT technology stack
SiteGPT anchored on the above requirements to inform their selection of modern technologies across their stack. SiteGPT’s distributed compute and logic engine is built on Cloudflare Workers and Cloudflare Queues. The front end administration tool uses Remix, a flexible framework for building and managing user interfaces. OpenAI GPT-4 serves as the underlying LLM generating chatbot content, while Pinecone stores and processes the vector embeddings. Finally, Fauna is used as the core distributed operational database for storing user application data, metadata, and context.
Application workflow
When a customer signs up for SiteGPT and logs into their SiteGPT admin dashboard, they first input the desired content links the chatbot will learn and derive answers from. This will concurrently generate a chatbot account in Fauna. The chatbot's associated links, along with their corresponding chatbotID’s obtained from Fauna, are then added to the Cloudflare Queue. This information is structured as an array of objects in the format {link: string; chatbotId: string}.
SiteGPT undertakes several tasks for each content link. It first scrapes the provided link, extracting all relevant website content. Next, SiteGPT utilizes OpenAI's embedding endpoint to create embeddings, transforming the content into numerical representations. These embeddings are then added to Pinecone, and the corresponding embedding ID metadata is stored in Fauna.
Once this set up is complete, users can enter a message, query, or request via the chatbot. The request is converted into an embedding, and SiteGPT retrieves the most relevant results from Pinecone using a top-k similarity search, formats the corresponding results, and calls OpenAI's GPT-4 API. SiteGPT then displays the received response from OpenAI to the user. Both the user's question and the corresponding answer are stored in Fauna. The vector ID in Fauna allows for easy association with the chatbot. In the background, SiteGPT records and stores this conversation history in Fauna, enabling website owners to review and access them conveniently through the SiteGPT dashboard.
Why a distributed serverless stack
Bhanu’s team prioritized proven modern technologies that would obfuscate undifferentiated infrastructure management and enable them to accelerate their development velocity of innovative features. Fauna, Cloudflare, and Pinecone all take a modern and distributed-by-default approach to delivering their solutions, allowing SiteGPT to focus on delivering the best solution for their customers. This ultimately leads to a world-class developer and user experience. “We built SiteGPT to enable businesses to deploy bespoke chatbots informed by their unique business context,” explained Bhanu. “We use Fauna to store all of SiteGPT’s application and user data because it naturally fits into our broader distributed architecture with Cloudflare Workers, alongside Pinecone as our vector database. This architecture delivers low latency to our customers with no engineering operations needed as our user base grows across global regions.”
Why Fauna
As SiteGPT’s user base rapidly expanded across eleven countries, SiteGPT needed a robust and scalable data storage solution. Fauna's distributed architecture provided the reliability and scalability required to handle the increasing demand and evolving geographic footprint of its user base, while its dynamic data model allows it to serve as the system of record for the application metadata, chatbot details, and user information. “Fauna is an excellent fit for our use case because it supports the disparate data we’re generating with its document model, but we can still execute complex operations on top of it,” Bhanu shared. “The fact that it’s delivered as an API allows us to focus on our business, and its distributed architecture allows us to keep latency low and helps us deliver a great experience to our customers.”
Flexible data model for metadata and context When a user prompts an LLM, it creates a historical record in the underlying database. Storing context data is essential for enabling SiteGPT’s AI model to generate relevant and coherent outputs based on the user's inputs and previous interactions. Context is typically semi-structured and more naturally stored in documents, compared to the tabular structure of a relational database. Unlike other document databases, Fauna’s relational database with a document data model supports semi-structured metadata without sacrificing the ability to traverse relationships between critical entities within an application via joins, filters, or foreign keys. This also extends to storing and querying embeddings metadata (sessions, mappings, and metadata corresponding to embeddings) and managing relations between the embedding metadata. The Fauna Query Language (FQL) is a powerful and expressive language that enables complex queries and operations against this context data — so developers aren’t cornered into workarounds to accommodate relationships between pieces of relevant data. The language is by nature composable and modular, allowing developers to query for documents at rest, encode sophisticated business logic and dynamically construct JSON-like result shapes that map to what the application requires - ultimately offering a familiar development experience to JavaScript or TypeScript.
To illustrate FQL’s ease of use and simplicity, here’s an example compared to SQL:

API delivery model and distribution-by-default Fauna is accessed via an API, which allows it to seamlessly integrate with the different pieces of SiteGPT including ephemeral compute functions like Cloudflare Workers delivered via HTTP. This reduces the total cost of ownership by eliminating connection pools needed to maintain TCP/IP connections, as well as the engineering time dedicated to maintaining integration code. Fauna's fully serverless model automatically scales based on demand, ensuring SiteGPT can handle varying workloads without manual intervention. Fauna automatically replicates data across various regions, directs queries to the nearest node for efficiency, and offers the highest level of consistency across distributed nodes via strict serializability. This guarantees that SiteGPT users are not presented with outdated or inaccurate data. Fauna’s consistency model allows SiteGPT to keep their application code in Cloudfare Workers lightweight and performant as they don’t have to build consistency rules into the application code, while its distribution profile enables SiteGPT to continue to grow to new regions without having to stand up additional database infrastructure.
Why Cloudflare Workers and Queues
Cloudflare Workers’ distributed architecture enabled SiteGPT to deploy chatbots closer to their end-users, reducing latency and improving responsiveness. This ensured that users across different countries could interact with SiteGPT's chatbots with minimal delay, resulting in a smooth and engaging customer experience. Bhanu explained, “We use Cloudflare for everything – storage, cache, queues, and most importantly for training data and deploying the app on the edge, so I can ensure the product is reliable and fast. It's also been the most affordable option, with competitors costing more for a single day's worth of requests than Cloudflare's monthly costs. The power of the developer platform and performance tools made it an easy choice to build with Cloudflare.”
Scalability and reliability Cloudflare's infrastructure provides a robust and highly available environment for SiteGPT's distributed compute functions. Cloudflare Workers and Cloudflare Queues offer exceptional scalability, allowing SiteGPT to handle an increasing number of user requests seamlessly. As the user base grows, these distributed compute functions ensure that the chatbot can efficiently process and respond to a high volume of concurrent interactions, maintaining optimal performance and user experience. With global redundancy and automatic failover mechanisms, Cloudflare Workers and Cloudflare Queues ensure that the chatbot remains operational, even in the face of potential disruptions or increased traffic loads – ensuring consistent availability and minimal downtime.
Low latency Cloudflare Workers and Cloudflare Queues enable SiteGPT to achieve low-latency responses, ensuring swift and real-time interactions with users. By leveraging Cloudflare's global network of edge locations, SiteGPT chatbots can deliver fast responses by processing requests closer to the user's geographical location, minimizing the time it takes for data to travel back and forth.
Why Pinecone
Pinecone excels at storing and retrieving high-dimensional vectors, which are essential for representing complex data such as natural language. “Similar to Fauna and Cloudflare, we chose Pinecone because we don’t want to absorb the hassle of managing our vector database and scaling it on our own,” Bhanu explained. “It handles everything automatically; we can tap into their API and be ensured that everything will work as it should, and be performant at any scale. We have over 2 million embeddings on Pinecone and it works without a hitch.”
Scalable storage and retrieval with real-time updates Pinecone provides a scalable and reliable infrastructure for storing and retrieving embeddings. As their user base grows, SiteGPT can seamlessly scale its storage capacity within Pinecone to accommodate the increasing volume of user data. This scalability enables the chatbot to maintain optimal performance even as the number of user interactions and embeddings continues to rise. Further, Pinecone allows for real-time updates of embeddings, ensuring that the chatbot can adapt and learn from new data in real-time. As SiteGPT continues to interact with users and collect feedback, Pinecone manages the retrieval process, enabling the chatbot to incorporate new knowledge and enhance its understanding through Retrieval-Augmented Generation (RAG). This agility helps SiteGPT stay up-to-date and deliver accurate and relevant information to its users.
Efficient similarity search Pinecone's vector database excels at performing fast and accurate similarity searches. As the user base expands, SiteGPT can leverage Pinecone to quickly find the most relevant embeddings for user inputs, enabling efficient and personalized responses. This capability enhances the chatbot's effectiveness and ensures a more engaging user experience.
Conclusion
SiteGPT's early success illustrates the benefits of harnessing modern technologies to build and iterate quickly, but also build for scale. By using Fauna, Cloudflare, and Pinecone together to complement the core AI component driven by OpenAI, SiteGPT is able to delight its customers with an experience they demand: fast and accurate. Ready to get started building with Fauna, Cloudflare, and Pinecone? Check out the Fauna and Cloudflare workshop or video tutorial, and the Pinecone and Fauna sample app. Sign-up for free today and get in touch with one of our experts if you have any questions.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.