

Modernizing from PostgreSQL to Serverless with Fauna Part 1
With modern development practices and efficiencies in mind, you can transition from a traditional relational application to a serverless document-relational database with maximum scale and no data consistency compromises.
Catalogue
Explore the other parts of the PostgreSQL to Fauna Modernization Series below:
Modernizing from PostgreSQL Part Two
Modernizing from PostreSQL Part ThreeIntroduction
Many web and mobile applications continue to be implemented atop traditional relational databases. Although many core components of these databases are five decades old, these designs are the most familiar to most database professionals. However, recently the choices have shifted toward more distributed, cloud-native options to support hyper-scale expectations. One of the popular relational database options is PostgreSQL (A.K.A. Postgres), which dates back to UC Berkeley’s POSTGRES project in 1986. It has supported SQL since 1994 and has been ACID compliant since 2001. Like other popular relational databases, Postgres is a client-server database at its core and continues to be enhanced by an active community, with Version 16.2 released in February, 2024.
Over its long history, Postgres has added a large set of extensions and options, including almost a dozen different data indexing options and many server replication alternatives. Multiple vendors have added data distribution options atop the core server code. In contrast, other vendors offer so-called “wire-level” compatibility atop redesigned engines that look more like key-value stores. However, most of the newest implementations still necessarily expose significant operational complexity in areas like partitioning complexity.
Some of the largest websites, driven by the requirements of serving billions of users, have led to the maturation of new database architecture alternatives, which motivate modernizing applications to leverage cloud-native, serverless, highly-distributed database options. Fauna strengthens relational data consistency among these newer alternatives while leveraging a cloud-native, serverless, flexible document model that abstracts most operational complexities from application developers.
You may be an application developer looking to build an application designed to scale well from the beginning. Or, you are a database professional looking to transition a Postgres application to minimize the amount of scaling impediments you may have encountered periodically as you continue building features. In either case, this article series is for you. It explores the process of transitioning an existing Postgres application to Fauna while ensuring that you build your database in a scalable way from the beginning.
In this first part, we provide a deep comparison between Fauna and Postgres while exploring how to implement and query a one-to-many relationship in a basic database. In part two, we extend the concepts to cover a many-to-many relationship and how to build a domain-specific language that avoids object-relational impedance mismatches. We explore advanced transactions with referential integrity in part three and suggest various modeling, optimization, and migration strategies.
Comparing Postgres and Fauna
Given that both Postgres and Fauna support relational database features, they share many important characteristics. Both support data relationships, serializable transactions, normalization, foreign keys, indexes, constraints, stored procedures, and many other typical relational database features. Both support ACID transactions and strict isolation levels. With Fauna default isolation levels can be considered stricter since it provides those guarantees even when data is distributed. Both are primarily aimed and are well suited for online transaction processing (OLTP) applications. Fauna focuses more on this use case because it is designed as a cloud-native database optimized for sub-second queries. At the same time, many Postgres implementations and extensions can be suited for more analytical use cases.
Notable Differences
Although both databases can implement most database requirements, their implementation varies significantly in some areas:
- Relational-model vs multi-model: Relational-model vs multi-model: Postgres is often described as an object-relational database with additional data types that support documents like JSON and JSONB, but it is primarily built and used as a traditional relational database. Fauna is often described as a document-relational database with JSON documents at its core but also includes a wide variety of relational features. In contrast to other common document databases, Fauna offers relational options and flexible indexing to maintain consistency. Further, it adds temporality by using MVCC for maintaining versions of documents as well as has an advanced ABAC system for access control.
- Schemas: Both Postgres and Fauna have a concept of logical databases that include schema records describing the collections, indexes, and security properties of the included records. However, Postgres enforces schema through an inflexible tabular model while Fauna gives users a choice. Fauna allows for a simple but sophisticated set of features that offers enforcement (for things like field names, required fields, data types, business logic, computed fields, etc) as well as the hybrid ability to allow additional dynamic components to documents at the same time. Further, Fauna offers migration blocks to allow for seamless schema changes over time.
- Database connections: Postgres expects persistent connections, like many similar relational databases. Most implementations must configure connection pools and have to be concerned with connection overhead and limits. Fauna uses stateless, secure HTTP connections and requires no connection management.
- Delivery Model: Postgres is built to self-host or to be hosted or managed by cloud providers, requiring managing server instances, read replicas, partitioning, and the like. There are vendors that claim that they provide serverless Postgres, but in many cases, there are still provisioning decisions to consider. On the other hand, Fauna was built from the ground-up with a fully serverless delivery model. Consumed as an API with a single global endpoint, there are no clusters, partitions, and replication to configure. Furthermore, the single global endpoint can intelligently route a request to the closest multi-active copy of the data, removing the need to design for HA.
- Distribution: When it comes to distribution in a traditional database, asynchronous replication is the most popular form of distribution which introduces eventual consistency and potential data loss. If consistency is required, synchronous replication is provided as an option, but it typically comes at a high price in terms of performance, especially if distribution across regions is desired. Although traditional databases like Postgres were not built with distribution in mind, many recent improvements and additions provide multiple options that supplement the non-distributed nature of its core engine. In contrast, Fauna is built from the ground up as a scalable, multi-region distributed database. It is inspired by the Calvin algorithm that speeds up data consensus by relying on deterministic calculations. Further, this distribution of data is transparent to the application developers and can accommodate data locality restrictions.
- Multi-tenancy: Although Postgres provides various options to create a SaaS application where you can have multiple tenants (whether across servers or within a single database), Fauna offers robust, native multi-tenancy configurations with a unique concept of child databases with arbitrarily deep nesting. Child databases are completely isolated from each other, with the ability to create separate permissions for child databases, and the child databases cannot determine whether there’s a parent database.
- Query Languages: The primary language used for Postgres is SQL or, more accurately, a SQL dialect. Although SQL has been around for many decades and is well known, documented, and standardized to the extent that it can be, every SQL database exhibits significant variations in the language. For example, to support JSON manipulation and event streaming, you will encounter significant differences between the SQL commands used in Postgres and other SQL databases like MySQL. Application developers will likely use an object-relational mapper (ORM) that adds some application complexity without removing the need to understand the Postgres-specific SQL conventions. GraphQL can be used with Postgres by adding extensions, of which there are many options to consider. Fauna provides its own native query language, FQL, which is designed to align with modern coding paradigms. Because of the nature of FQL and other design considerations, Fauna requires no ORM and is not susceptible to injection. The choice for a custom language is rooted in Fauna's scalable and distributed design. It’s designed to prevent long-running transactions, maximize performance in distributed scenarios, be highly composable to reduce round-trips and overall latency, and have a transparent and predictable query plan. Many of these characteristics will become evident in this article and its subsequent parts as we cover FQL extensively in the coming sections.
Postgres and Fauna: Terminology Mapping
The following table summarizes how Fauna concepts relate to Postgres counterparts and, in most cases, also apply to similar terms used with other relational databases. This table comes from this blog, and the Fauna documentation provides more details on these concepts and many other common SQL commands and concepts here.
| POSTGRES | FAUNA | DETAILS |
|---|---|---|
| Row or record | Document | In Postgres, a record (or row) represents a distinct database entry, and it must conform to the containing table’s column definitions. In Fauna, a document represents a nested structure of fields and their values, with no specified structure or types. Each document, even in the same collection, can have its own independent structure, making the documents schemaless. Also, each document is versioned, storing the history of a document’s mutations from creation to deletion. |
| Table | Collection | Tables store records, collections store documents. In Postgres, a table’s column definition specifies the structure for all records in the table. The column definition specifies the names and types of values that can be stored in a column. In Fauna, collections are a container for documents, imposing no specific structure on those documents. |
| Primary | Region | Fauna has no primary or secondary concept, all regions can serve reads and writes. |
| Secondary, standby, replica | Region | Fauna has no primary or secondary concept, all regions can serve reads and writes. |
| Replication | Replication | Fauna’s replication is semi-synchronous and does not require any operator management. |
| Sharding, partitioning | Not Applicable | Fauna does not require the operator to manage sharding or partitioning in any way. |
| Primary Key | Document ID | The unique identifier of a document. |
| Foreign Key | Reference (Ref) | A pointer from one document to another. |
| Index, materialized view | Index | Fauna merges the concepts of indexes and views. Indexes must be explicitly referenced. |
| Transaction | Transaction | Both Postgres and Fauna support ACID transactions. |
| Schema, database | Database | Both Postgres and Fauna have a concept of logical databases that include schema records describing the collections, indexes, and security properties of the included records. In Postgres and other relational databases, a schema refers to the set of table definitions and constraints defined in that database. The schema is enforced so that no row violates its table definition or constraints. In Fauna, database definitions also include child databases with arbitrarily deep nesting. A Fauna database contains schemaless documents with no schema enforcement available at the document level; however, validation functions may be used when necessary. |
| Stored procedures, user-defined functions | User Defined Functions (UDF) or Functions | Fauna supports user-defined functions written in FQL. |
Tables and rows are collections and documents in Fauna just like in other document databases. An index in Fauna is a combination of an index and a view as we know them in a traditional database. We’ll directly query indexes for data since indexes contain data, similar to consistent ordered views. User Defined Functions (UDFs) are similar to Stored Procedures except that, in contrast to Postgres, both queries and UDFs are written in the same language in Fauna, while in Postgres, you would split to the PL/pgSQL language for a stored procedure. Fauna users typically use UDFs much more frequently due to the easy transition from a query to a UDF.
From Postgres to Fauna: Building the Basics
In this section, we’ll learn how to create a database, a collection, insert some documents, and query them. We will focus on modeling one-to-one and one-to-many relationships in this article; we will model a many-to-many relation in the next article and cover other modeling options in the third and last installment. We’ll use a well-known Postgres tutorial that provides a database model of a DVD rental business. The model of the DVD rental application looks as follows:
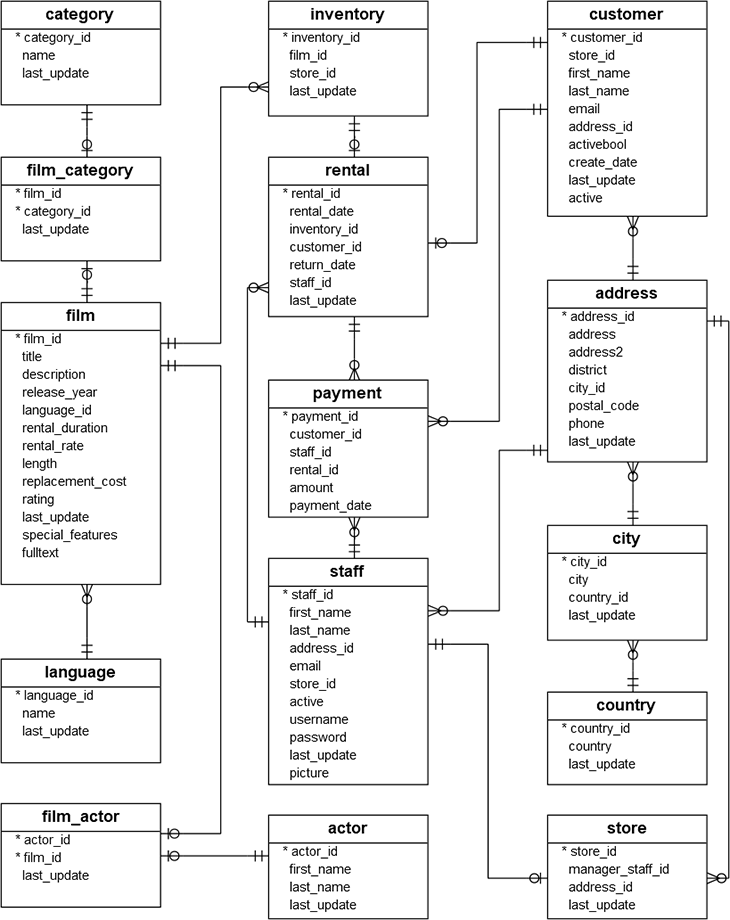
Source: PostgreSQL Tutorial - **https://www.postgresqltutorial.com/postgresql-sample-database/
The database schema has “film" at its center and allows customers to rent DVDs from different stores around the country, supports shopping baskets, as well as film, payment, store, and customer management. Thanks to the normalized model, it supports many access patterns: customers can find films by category, rating, release year, title, description, or actor. The staff can retrieve where a film currently resides or retrieve a list of overdue rentals.
Creating a new database
In this section, we’ll create the database. Even if you don’t follow along, this 2-click process (plus typing a name) shows how different the database-creation process is compared to setting up a traditional database.
Sign up
Fauna is a cloud database. There is no setup of hardware or configuration necessary. All you need to do is go to dashboard.fauna.com and sign up for an account.
Create the database

Click NEW DATABASE to create a new database which will instantly be created.
Fill in a name for your database and click CREATE.
Now that you have created a database, you can follow along by pasting the provided code in the dashboard shell (or play around with the UI instead to create collections/indexes etc). Of course, you can also send queries to Fauna using one of the drivers or the terminal shell. The shell is built around the JavaScript driver behind the scenes. When writing FQL, we are not writing strings but rather functions, although that might not be obvious as we use the dashboard shell.

One-to-many relations
Let’s start with a small and easy subset of the model and extend it gradually. The film and language relation is a many-to-one relation that should be common in relational database models. Since the model remains quite simple, we’ll render it more interesting. Instead of one language, we’ll add both a spoken and a subtitle language. This will allow us to show a simple form of 1:1 as well as 1:M. As we move through this guide you can compare the examples with Fauna’s relationship documentation for more examples.

Creating the language collection
In Postgres, there are tables that contain rows; in Fauna, we have collections that contain documents. A key difference here are the native elements exposed at the document/row level. Specifically, every Fauna document natively has an “id” and a timestamp (“ts”). As each document is stored with MVCC, with older versions being held for a configurable TTL, Fauna also supports temporal querying (resolving queries as of a given time). Here is a base document in Fauna:
{
id: "406214110775083073",
coll: <collection>,
ts: Time("2022-01-14T17:00:14.430Z"),
fields...
}
To begin our walk through, let’s create a new collection. We could use the dashboard interface but just like in SQL, manipulation and creation of collections, indexes, security roles, or even databases can be done entirely in the query language. To create the language collection, we can also paste the following FQL code snippet in the dashboard shell:
Collection.create({name: "language"})Creating language documents
Now that we have a collection defined, we can start to add documents to it. To do so we use the ORM-like syntax of FQL to call the create() function of the newly created language collection:
language.create({name: 'english'})
language.create({name: 'french'})
The input to the create() function is a JSON object. This allows for an easier developer interface as well as a dynamic means to model data. Once we have executed the create() statement, we can take a look at the document by viewing what was returned.
The “name” field is a user-defined field and it follows the system fields for “id”, “coll” and “ts”.
- id: a unique reference to the document. The presence of references doesn’t mean that we can no longer use other IDs in Fauna. We’ll see the difference between native Fauna references and IDs shortly when we start querying.
- coll: is the name of the collection that this document belongs to.
- ts: the timestamp of the document, which is automatically updated when the document is adapted. Fauna’s timestamp is part of temporality features that provide time travel and support the streaming capabilities.
You’ll notice that the ID for the document was auto-generated. This commonly removes the needs for an application to generate its own IDs. If desired, a newId() function is available for generating new, IDs that are globally unique. With distributed databases and applications that scale it is common to avoid incrementing IDs as they can create performance bottlenecks. The preferred means of generating IDs is to either allow the document creation to generate the ID on its own (use the ID the system already generates for the document) or to generate a user-defined unique ID that can be stored in a custom field (via the newId() function or the application creates a smart ID). If a custom ID is created then you should add an index and likely a unique constraint to the field.
Note: Your reference IDs will be different. If you are following along, you can grab the reference ID of any document from the create() output.
Creating the film collection and documents
Now that we have a language document, as well as its ID, let’s create some film documents. To store the film documents, we need a film collection:
Collection.create({name: "film"})Let’s create a couple of simplified film documents. We actually have several potential choices for implementing the relationship between films and languages since Fauna is both a document and relational database. But they mostly break down into two methods, embedded and normalized. We’ll start with the normalized as that’s the most common when coming from Postgres.
We will make it more interesting and add both spoken language and subtitles language, so there are actually 2 foreign keys in our example. We will refer to the previously created language by storing the native reference in the document as follows (again, your reference IDs will be different):
film.create({
title: "Academy Dinosaur",
language: {
spoken: language("288878259769180673"),
subtitles: language("288878259769180673")
}
}
)A second document might be:
film.create({
title: "Back to the Future",
language: {
spoken: language("288878259769180673"),
subtitles: language("288878259769180673")
}
}
)Note in the above examples that the “foreign keys” for the language are actually document references.
Querying basics
Now that the test data has been built, let’s move on to how queries work in Fauna. When moving from Postgres to Fauna you’ll find the same query elements exist in FQL as are in SQL, just more simplified.
The simplest Postgres query is easy since SQL is a declarative language where you describe what you need instead of how you want it to be calculated.
SELECT title FROM film where id = '406214477539704900'In contrast, FQL is based on typescript and operates like an ORM. Instead of picking fields, then tables then joins then filters, Fauna follows a natural path of picking your document/s and then filling out which fields you want. The FQL pattern is to start with your collection, add your index, then add any filters or sorting as chained methods, and then add your “projection” where you choose your output fields. The FQL version of the above SQL would be:
film.byId("406214477539704900") {
title
}This article focuses on replicating a traditional relational model in Fauna, providing an opportunity to introduce you to FQL. If you want to dive deeper into the fundamentals of FQL, here is an excellent guide that starts from scratch and here’s a guide to translating basic SQL queries to FQL.
Pagination
When a query returns multiple documents, the response is a set. To ensure scalability, sets over 16 documents will automatically be paginated. This is a common best practice when consuming most interactive APIs. Since we added two films, we can add a size parameter to see the pagination in action. Fauna will return an after cursor to move to the next page.
film.all().paginate(1)Which now returns an array of film references:
{
data: [
{
id: "406214477539704900",
coll: film,
ts: Time("2024-08-14T17:06:04.210Z"),
title: "Academy Dinosaur",
language: {
spoken: language("406214110775083073"),
subtitles: language("406214110775083073")
}
}
],
after: "hdWCxmRmaWxtgcqEY2FsbID09oCBzUoFoyw/jlAAQQQGwYIaZr0HPBogyFWAAQ=="
}We can use the “after” cursor to get to the next grouping:
Set.paginate("hdWCxmR...")Data architects who have experimented with multiple ways of pagination within Postgres may want to know what kind of pagination this is. Fauna’s approach is close to the KeySet approach and cleverly takes advantage of snapshots to ensure that pages do not change when data is adapted. This is possible since everything we query in Fauna is backed by a sorted index. Just like Paginate, indexes are mandatory to avoid issuing underperforming queries.
Although we don’t appear to be using an index in the query above, all() is actually using a built-in index based on the “id”. The all() function is good for using on small data sets but it is recommended to normally be using an index to limit the number of documents to be processed.
Querying one-to-many relationships
So far we’ve only queried from a single collection. Next we’ll move into queries that emulate joins and combine the data from multiple documents. What you’ll see is that, due to the document references being placed during the write, the joins between documents becomes little more than the engine following reference links when found. And, merely listing the desired fields from the related documents is all that is needed (not the table join semantics).
Querying normalized data with native references
Earlier, we chose to normalize the data and store references instead of embedding the data into the documents. Below is what the document would look like for the film “Academy Dinosaur”:
{
id: "406214477539704900",
coll: film,
ts: Time("2024-08-14T17:06:04.210Z"),
title: "Academy Dinosaur",
language: {
spoken: language("406214110775083073"),
subtitles: language("406214110775083073")
}
}Note that the relationships between the film document and their corresponding language documents exist as references, not foreign keys.
In Postgres the SQL developer would have to write the additional join statements. That would look as follows:
SELECT * FROM film
JOIN "language" as spol ON spol.language_id = film.spoken_language_id
JOIN "language" as subl ON subl.language_id = film.subtitles_language_id
LIMIT 16In Postgres, we define the join we would like to see and rely on the query optimizer to select the right algorithm. If the query optimizer makes a wrong judgment, query performance can suffer significantly. Depending on the data and the way we join it, the join algorithm could differ and even change when the size of the data changes.
Due to the scalable nature of Fauna, we want predictability in terms of price and performance. Although joins can scale in general, their performance will depend on many factors. To ensure predictability and execute queries efficiently, we follow predetermined references.
In Fauna, you become the optimizer when you create your documents and form your queries. Fauna’s engine will then automatically gather the referenced documents for you.
In the following example we specify which return fields we want, just like a SELECT clause. In the case of FQL, the return field list is at the end, wrapped in curly brackets and is called a “projection”. Here we’ve asked for the title field in the film document and then the related spoken field in the language document.
film.byId("406214477539704900") {
title,
language {
spoken
}
}{
title: "Academy Dinosaur"
,language: {
spoken: {
id: "406214110775083073",
coll: language,
ts: Time("2024-08-14T17:00:14.430Z"),
name: "english"
}
}
}Note that Fauna used the value in the spoken field, which was a stored reference to a specific language document, to automatically gather that document and return its value. And, if we wanted to refine it further, we could continue to asking for just the language name:
film.byId("406214477539704900") {
title
,language {
spoken {
name
}
}
}{
title: "Academy Dinosaur",
language: {
spoken: {
name: "english"
}
}
}So, the projection section of the query is for listing which fields to return and Fauna follows any references it finds. If it’s a value, then return it. If it’s a reference, then follow it. Whether it’s an embedded object or a reference to another document, you can use object notation in the projection clause.
This also works for arrays, to add the ability to relate “many” other documents. A document can have an array of references in which Fauna would traverse each reference and return the underlying document (or requested subset of fields). We could create a new relational model where the language of the film was an array of references.
film.create({
title: "Batman",
language: [ // note the array of references
language("406214110775083073"),
language("406251657205121089")
]
}
)Fauna will follow each reference when the array is chosen for return.
film.byId("406251968497975364") {
language
}Note the return is an array of the references documents.
{
language: [
{
id: "406214110775083073",
coll: language,
ts: Time("2024-08-14T17:00:14.430Z"),
name: "english"
},
{
id: "406251657205121089",
coll: language,
ts: Time("2024-08-15T02:57:01.500Z"),
name: "french"
}
]
}This effectively creates a one-to-many pattern. Where a parent document has an array of foreign key IDs in the form of document references.
Additional common query functionality
Note that so far we’ve just covered the most basic form of querying with FQL, with the intent of highlighting how to store and use relationships. Fauna is a full featured operational database with a sophisticated set of query tools. With Fauna you can create indexes on fields, computed fields, array elements and embedded objects as well as you can use method chaining to add operations to query sets like filtering, ordering, pagination or forEach and even create multi-step queries or functions with variables and procedural logic. For more information about additional language features look here. For FQL examples look here. For translations from SQL to FQL, look here.
Modeling relationships
Fauna is a document-relational database and supports both patterns. When migrating from Postgres it is most common for data models to be normalized. This will continue to work in Fauna. For the most part, the change is in how the foreign keys are stored. For Fauna, instead of storing the foreign keys (an arbitrary ID), Fauna has you store the direct document IDs as references. This serves to not just link the appropriate record but also to bypass the need for an optimizer to figure out how to find this record at compile time (determine the correct index and correct search approach). Optimizers not only take time during execution, but it is not uncommon for optimizers to choose the wrong index or for there to be out of data statistics. The Fauna approach ensures fast, predictable execution of the relationship.
Due to also supporting document patterns, there are also some situations where you may want to consider optimizing your model. In general, a relational model is designed around storage patterns, storing the least amount of data. A document model is designed more around access patterns. To optimize for speed and scale, read and write operations are reviewed to ensure that the least amount of work is done for each. And typically this means answering questions on-write instead of on-read. This can lead to things like embedding data instead of normalizing it (like an order’s shipping address), using inserts instead of updates (all changes are inserts with a timestamp and the most recent is the current state), etc. These types of optimizations can be easily applied in Fauna due to Fauna’s schemaless documents as well as its online features where indexes, field changes and data migrations can be done online and without application downtime.
A common example of a document approach for storing related data is to embed it. This is to say that instead of putting it in another collection and storing a reference, you would put the data inside the parent document as a field, array or object. In this case, if desired, we could add the languages as embedded objects inside the film documents. This is a common pattern when the related data is small, it doesn’t change and is frequently accessed together. If that is the case then embedding saves an additional IO versus a normalized approach. An example of embedding the language:
film.create({
title: "Academy Dinosaur",
language: {
spoken: { name: "English" },
subtitles: { name: "English" }
}
}
)Fauna's querying and indexing capabilities do not change based on whether documents contain nested data or normalized. That doesn’t mean that denormalization is the recommended practice, but it does become more attractive as a technique to optimize read performance. We’ll dive into some advanced optimization techniques at the end of this series and will show how FQL can actually help you hit the sweet spot between flexibility, optimization, and data correction.
In some databases, indexing flexibility might suffer when nesting objects. However, Fauna’s indexing is built to be flexible regardless of whether the data is stored as nested objects or normalized. Further, Fauna indexes work equally well on nested values or arrays and can even index all values of an array (MVA).
Common optimizations
When moving from a relational database to Fauna, the following are considerations for ways to optimize for usage or data patterns.
- Normalizing versus embedding. In order to optimize for read execution, when applications scale it can be better to store all relevant data inside 1 document instead of spreading it out over multiple documents. An example would be embedding a shipping address for an order. Since this is unlikely to change, is a small amount of data and is likely to be included in a query of the order, it may be optimal to store it with the order and avoid the additional read IO in a query.
- Updates versus Inserts. As systems scale, it is generally beneficial to avoid changing any one item too often. Inserts can be done with more concurrency than updates, on a single logical value. Thus it is an optimization to change the data model and access patterns from updating a single document to inserting new documents with the new value, along with a timestamp. This, plus an index on the timestamp, allows for both the latest state to be gathered quickly as well as a version history to be included. With Fauna’s TTL (time to live) feature for documents it is simple to auto-clean the data as well.
- Incrementing integers. It is common for every system to need unique IDs and for relational systems to use incrementing integers for that purpose. In distributed systems it is far easier to generate unique IDs when they are random. This avoids locking contention. So for this purpose it is best practice to either let each document’s ID become that “rows” ID or to use the newId() function to generate a globally unique ID. There is also a sequence function available for generating a set of sequential numbers.
- Covered indexes. These are the same between Postgres and Fauna, but it is a common optimization to make sure that most all reads are either needing all/most of the document or have their few return fields covered by the index. This removes the need for an extra IO if the index can fully satisfy the query. Fauna has no restrictions on the number of indexes per collection. It is a best practice to ensure that the indexes planned for the Fauna model cover as many of the queries as possible.
- Sorted indexes. In applications meant for scale, design work can be done to avoid having to process things at run time (which could either be over a large number of records or consume a lot of server compute). An example of that is to use a sorted index (an option in Fauna) to maintain an order to documents. This enables fast selection for a TOP N type query or quickly returns the most recent entry when the sorted field is a timestamp.
- Computed fields. Fauna allows for sophisticated logic to be added as computed fields. This can allow for some data to be logical instead of physical as well as these fields can be indexed. This can be helpful in enforcing business rules, limiting the size of data, simplifying indexes and models. An example would be a “state” or “status” field which can then be logically computed and indexed, allowing for processes looking for certain values to gather them easily and without having to scan a lot of data looking for qualifying items.
Summary
We covered a lot of ground here. First, we outlined the key motivations why application developers are considering moving away from traditional relational databases like Postgres. Even with Postgres’ feature maturity, scaling traditional database applications horizontally is still challenging, especially if the application is to handle very significant traffic loads. We covered key differences between Postgres and Fauna and provided a terminology mapping that should have demonstrated the equivalence of many shared concepts.
We went through the process of creating a database, building a couple of collections, and inserting documents in those collections to illustrate a typical one-to-many database relation from one collection to another. We covered using native Fauna references, as well as the alternatives of embedding and denormalizing the data, as well as using user-defined IDs, and how those decisions change how we build queries to retrieve the data in all those cases.
This sets us up for part two, where we use a many-to-many relationship example to cover more modeling strategies and extend the idea of writing a domain-specific language with FQL. Finally, part three focuses on referential integrity as well as additional modeling, optimization, and migration ideas. By the time you complete this journey, you should be armed with a solid foundational strategy to transition your Postgres-driven application. This strategy will provide you with enough guidance to have a scalable and performant resulting system from the beginning. It will also set you up with a composable and testable code base that will help you maintain your code leveraging modern application best practices.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.