

Modernizing from PostgreSQL to Serverless with Fauna Part 2
Introduction
In part one, we got our first taste of Fauna relational modeling using the data model for a DVD rental business (adapted from a popular Postgres tutorial). In this article, we’ll continue adapting this borrowed data model to learn how Fauna can query many-to-many collections in a normalized fashion.
Catalogue
Explore the other parts of the PostgreSQL to Fauna Modernization Series below:
Modernizing from PostgreSQL Part One
Modernizing from PostreSQL Part ThreeModelling many-to-many relationships in Fauna
Typically, a film has multiple categories, and a category has multiple films, so let’s slightly adapt the model again (in green) to turn it into a many-to-many relation.
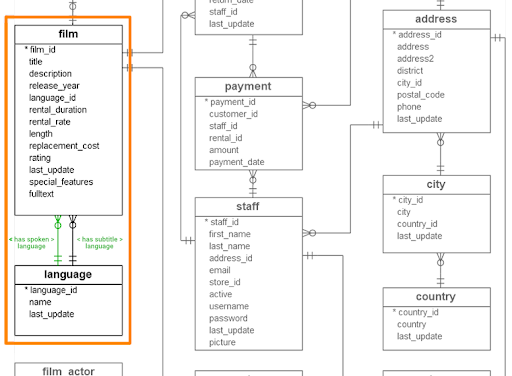
Storing the many-to-many relationships
Given this example, we will start by building out the model and inserting data. We’ll start by creating the two base collections in Fauna and then add some data modeling the relationships.
First, let’s make the category collection with the below FSL statement. This collection schema definition tells Fauna there is one required field, name, and it must be of type String, but the wildcard constraint says any other fields can exist in documents as well. The schema definition is optional in Fauna, as your collection can be serverless if that suits your needs better. For more information on field definitions, schema enforcement, and migrations, please see the documentation.
In addition, there is an index and a unique constraint on the field named name. The index is so we can query the collection by category.name, e.g. “Horror” and the unique constraint is so we can only have one document with each name in the collection.
collection category {
name: String
*: Any
index byName {
terms [.name]
}
unique [.name]
}Next, Let’s add the film collection. The schema definition tells Fauna there is one required field, and it must be of type String, but the wildcard constraint says any other fields can exist in documents as well. In addition, there is an index and a unique constraint on the field named title for the same reason we added one on the name field in the category collection
collection film {
title: String
*: Any
index byName {
terms [.title]
}
unique [.title]
}Now, let’s add some documents.
// Add some category documents
category.create({name: "Horror"})
category.create({name: "Documentary"})
category.create({name: "Romance"})
// Add a film document
film.create({
Title: "How Bob Got His Garage Back",
Description: "An epic tale of romance, danger, and laughs to show just how amazing woodworking can be."})With the film and category documents, do you relate these collections directly, or…?
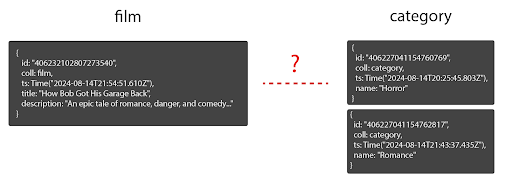
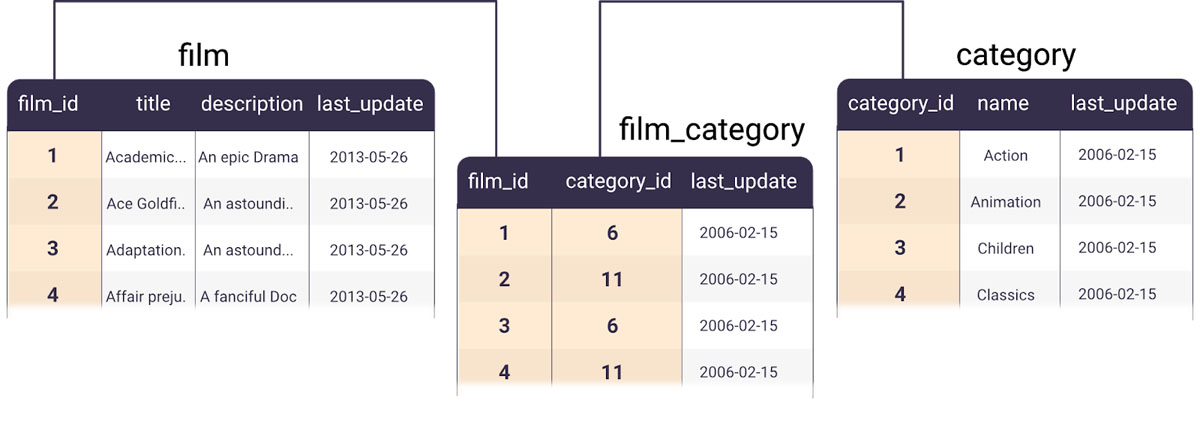
In a traditional relational database, we would probably opt for an association/junction table to normalize this relationship to have a list of limited category options the app must use. This would allow a film to have multiple categories and a category to have multiple films. Postgres is tabular so it cannot store things like arrays with many values that can be indexed so this would be the common way to solve this relationship.
Since Fauna is a combination of a relational and document model, there are many possible ways to model this:
- Model the relation with an association table (similar to the Postgres approach)
- Store an array of category collection references in the film document
- Store an array of categories as Strings in the film documents, but with an enumerated set of possible values for the category array enforced in the film collection’s schema
The trade-offs between different solutions typically boil down to whether you are optimizing for writes or reads, and the degree of flexibility you desire. We'll look at these other approaches later, but first, let's show you how we'd handle the Postgres model, as that's the likely form you'd be migrating over to fauna. We don't have to know the access patterns. This first pass is about modeling what's coming from Postgres. And since it can't embed or support indexed arrays (JSON values in columns cannot be joined or indexed in a way that would work here), this is the most likely scenario.
Let’s continue with how Fauna supports the association table model. Similar to the Postgres approach, we’ll create a new collection called film_category where each document will store a reference to both a film and a category. Joining a film with a category will require us to go through that relation document.

With the films and categories already loaded, let’s move on to adding the necessary association collection. The below collection schema definition tells Fauna there are two optional fields, but if they do exist, they must be references to docs in other Collections. Fauna not only allows for enforcing that fields exist but also allows you to define the type and even that it is a specific type of document reference.
collection film_category {
film: Ref<film>?
category: Ref<category>?
}
Now we’ll add some documents into the association collection that will serve as links between the film and category documents. With Fauna you don’t have to actually know the foreign keys when doing the association document creation. Another method is to use sub-queries to find the references for you. Each of these document creation operations queries an index on both the category and film collections to get the matching documents and then saves references into each film_category document.
film_category.create({
category: category.byName("Romance")!.first(),
film: film.byTitle("How Bob Got His Garage Back")!.first()
})
film_category.create({
category: category.byName("Horror")!.first(),
film: film.byTitle("How Bob Got His Garage Back")!.first()
})The resulting association documents will look something like this:
{
id: "406236304934699076",
coll: film_category,
ts: Time("2024-08-14T22:53:00.450Z"),
category: category("406227041154760769"),
film: film("406232102807273540")
}Notice the category and film fields are traversable references to documents in those Collections, not the documents or fields themselves. The “joins” have been pre-built so that Fauna does not need an optimizer at run time to determine the best access methods.
Keeping primary keys unique
Once we create a document linking a film with a category, we need to make sure that we don't accidentally create a duplicate document with the same content.
Fauna is schemaless by default, but also offers the ability to layer on full schema enforcement, including unique constraints (visit Fauna's schema docs to learn more about its full suite of capabilities). We can optionally add unique constraints to our primary keys to ensure that the same primary key does not exist twice. These constraints are enforced transactionally by creating a constraint on the fields of that collection. Defining the constraint below will make sure the combination of category and film is always unique.
collection film_category {
film: Ref<film>?
category: Ref<category>?
unique [.category, .film]
}
For more information on unique constraints, take a look at the docs.
Querying the relationships
Films and categories have a one-to-many relationship because we need multiple categories for a given film but not vice versa. So, the simplest solution was to store the category references on the film document itself.
In contrast, our film-to-category relation is many-to-many, so we stored the film-category references in a new film_category collection instead of on the film document.
With Fauna, an index's terms define exact matches, while the index's values define what we can sort on (you could also do range queries, but that’s not applicable to this data). Terms and values combined are what the index covers and therefore the data returned from the index.
Note: When querying using an index you can request more fields than the index “covers,” but this is less efficient as Fauna must retrieve that data from the source documents to get those non-covered fields. Therefore it is best practice to have an index satisfy multiple application access patterns to avoid having Fauna need to additionally look up the source document..
As shown below, create an index called categoryByFilm with a term of the film field, which is a reference to a film document in the film collection, and a value of category, which is a reference to a category document in the category collection.
collection film_category {
film: Ref<film>?
category: Ref<category>?
unique [.category, .film]
index categoryByFilm {
terms [.film]
values [.category]
}
}
In order to query the newly created index categoryByFilm we need a reference to a film. To do that, we will use a sub-query. Queries in FQL are executed from the inside out. In the case of the query below, the query to the byTitle index on the film collection with a film’s name is executed first to get the film reference. Since there is a unique constraint on the title in the film collection schema, I can use the .first() method in FQL to grab the first item of the Set returned by the index. If that unique constraint was not there, I’d have to use either map() or forEach() to iterate through the Set returned by the index.
film_category.categoryByFilm(film.byTitle("How Bob Got His Garage Back")!.first()) {film, category}You’ll note that the differences with Postgres are:
- The data in the association table are references instead of foreign keys
- The FQL accomplishes joins differently than SQL.
For this query, you would likely want to paginate through the results set as there could be many matching documents returned.
Optimizing using Fauna's capabilities
The many-to-many pattern is similar to what you’d use in a traditional RDBMS and works in Fauna. However, because Fauna supports both normalization and denormalization, there’s potential for optimization to reduce the number of collections, increase performance, and potentially lower costs.
In the case of using an association table like above, it takes multiple writes to build, and several reads in the query. While this will work in Fauna, since Fauna can handle more complex document structures, like arrays and arrays of references, we could skip needing an association table and just store categories directly in the film table. This would then remove the additional collection as well as the maintenance of this collection. Let’s look at two possible optimizations and the pros and cons of each.
Reducing to one-to-many with an array of references
With this specific film data example, instead of having the association collection and doing a relational database style many-to-many relationship, an optimization could be to embed an array of references to documents in the category collection into each of the film documents. Then put an index on the categories field in the film collection. With this method, when a film is read from the byTitle index, you read the main film document and just the categories referenced in one simple transaction with a projection.
This removes an entire collection, film_category, but still enables getting a film and all related categories or all films with a certain category. This would reduce storage and read/write IO. For the relational style many-to-many style shown above, to read a film and its three categories, it’d be at minimum six read operations. With this optimization, it’d be four read operations.
In this example, it queries the byTitle index to get the film by name and uses a projection to limit the fields returned and to traverse the relationships to the category collection. Do this by passing in the film’s name, and getting the first one back as indexes return a Set, but there is a unique constraint on the title field, so there will only ever be one document returned. I then project the title and category fields to be returned from the index.
film.byTitle("How Bob Got His Garage Back")!.first() {title, category}If trying to get all the films by category, query the byCategory index with the value of the category wanted and a subquery to get the reference from the category collection.
film.byCategory(category.byName("Horror")!.first()) {title, category}Then paginate through the resulting Set.
Denormalization into one collection of documents
An even better optimization utilizing Fauna’s capabilities would be to completely denormalize the categories to be an array in a field in the film document but enforce in the schema the values must be from an array of enumerated values supported for the category field.
collection film {
title: String
category: Array<"Romance" | "Horror" | "Comedy" | "Documentary">,
*: Any
index byName {
terms [.title]
}
unique [.title]
}With this method, the application needs only to read and write to a single collection, one place on disk, thus optimizing for read/write operations as it’d be going from the original six, down to four, and now with the denormalization method, to just one I/O. here is an example of the resulting document in the film collection.
{
title: "How Bob Got His Garage Back",
description: "An epic tale of romance, danger, and laughs to show just how amazing woodworking can be.",
category: [
"Horror",
"Romance",
"Comedy"
]
}With these two patterns, it is recommended for any existing many-to-many relationships in Postgres, to judge if one of these two optimizations is a better fit. If so it is rather easy to implement as it would just be updating the parent collection’s schemas to have arrays instead of individual values and the array data could be sourced easily during a data migration. If you truly need a many-to-many design that is completely optimized for Fauna, refer to the documentation.
Conclusion
This concludes part two. In the part three, we'll dive into uniqueness constraints, referential integrity, optimizations with indexes, and others.
We’ll briefly look into these modeling strategies and the different trade-offs and techniques to ensure data correctness even when duplicating data.
The Fauna service will be ending on May 30, 2025. For more information, read the announcement and the FAQ.
Subscribe to Fauna's newsletter
Get latest blog posts, development tips & tricks, and latest learning material delivered right to your inbox.